When recreating the example study by means of the genuine search interface provided by the literature databases, the first step, i.e. thinking about the time spans and databases available, does not differ from the work with WordSmith. However, by looking at one time span in particular, e.g. 1650-1699, the first disadvantage of the search interface becomes obvious: It does not support choosing texts from multiple databases but can only handle one database at a time.
4.3.1 Searching the EEPF
4.3.2 Analysing the frequency
4.3.3 Summary
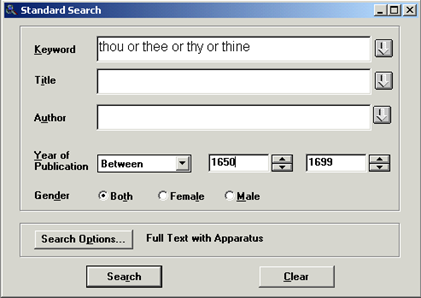
Having entered the respective database, in this case the EEPF, it is possible, however, to narrow the search down to publications from the wanted time span. Additionally, the search words cannot be separated by slashes, as is possible in WordSmith, but must be connected by operators according to Schlüter’s description in “3.1 Search syntax”. Consequently, if one wants to search for all occurrences of thou, thee, thy and thine, the line typed into the Keyword field has to be thou or thee or thy or thine (cf. figure 5). The outcome of this query amounts to 8,553 hits. When it comes to looking for variant forms, the "Keyword Browse" button - the arrow to the right of the keyword input field - offers a convenient way to select the wanted words. It makes it easy to search for possible variants and subsequently select all of them at a time by clicking on them while holding "Ctrl" on the keyboard. Compared to the WordList function, which is used in WordSmith to obtain variant forms, this is indeed a more elegant solution.
Figure 5: Standard Search in the historical literature databases
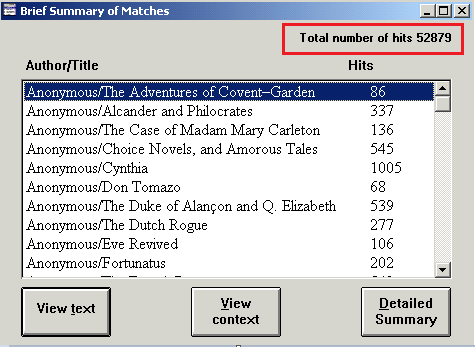
Since the interface of the literature databases offers no possibility to make a word list or count the total number of words inside the texts, the only way to receive a meaningful number is to put the 8,553 hits in relation to the number of occurrences of both the singular and plural pronouns combined, i.e. thou, thee, thy, thine, ye, you and your. Thus, a search for thou or thee or thy or thine or ye or you or your yields a result of 52,879 hits, which can serve as a reference point for analysing the frequency of the singular pronouns (cf. figure 6). Now, one can state that the singular pronouns mark 16.175 % of the overall number.
Figure 6: Brief Summary of Matches in the historical literature databases
Nevertheless, if we wanted to include the English Prose Drama database in the study, we would have to follow the same procedure there again and calculate the sums of the two figures. Again, the following steps would be to repeat the whole procedure for the remaining time spans and to display the results of a diachronic comparison visually by means of a chart. This graph would then ideally show a decline similar to the one in figure 4, though the standard of comparison was a different one there (overall word numbers rather than total numbers of second person pronouns).
The comparison of the application of WordSmith with the genuine interfaces of the databases has clearly shown that the usage of raw data offers more possibilities for searching texts and is generally the more comfortable option. In the case of this example, this became obvious as the interface does not allow for creating a word list, which thus prohibits depicting the results as instances per million words. This circumstance is also true when it comes to displaying, saving and sorting results. However, as it was also the case here, bypasses can be found and most databases offer possibilities to compensate for at least some deficits (cf. 3.2 of Schlüter’s chapter).
Created with the Personal Edition of HelpNDoc: Free EBook and documentation generator