4.2.1 Choosing texts
4.2.2 Searching the texts
4.2.3 Analysing the frequency
4.2.4 Repeating the procedure
4.2.5 Generating a chart
The first step of this example analysis conducted by means of the raw data and WordSmith is to choose the texts to be analysed. Since the result should give an insight into diachronic change, one must firstly think about the period that each time span should cover, that is how fine-grained the analysis will be. While time spans of 100 years each seem to be too rough and an interval of 25 years would be highly time consuming and perhaps overly fine-grained for this example study, an analysis that regards time spans of 50 years seems appropriate. Additionally, the overall period of time covered by the study should not reach into the 20th century but end with the year 1849, assuming that the general trend will be clearly visible by then. Considering what is known about the evolution of you, the starting point of the study should be as early as possible, beginning with the first text of the EEPF dating from 1518. Accordingly, the databases that can be taken into consideration for each time span are as follows:
1500-1549 |
EEPF (1518-1549), EPD (1540-1549) |
1550-1599 |
EEPF, EPD |
1600-1649 |
EEPF, EPD |
1650-1699 |
EEPF, EPD |
1700-1749 |
EEPF (only 1700), EPD, ECF (1705-1749), AD (1714-1749) |
1750-1799 |
ECF (1750-1780), NCF (1782-1799), EPD, EAF (1789-1799), AD |
1800-1849 |
NCF, EPD, EAF, AD |
Starting at the first time span, that is 1500-1549, the next step is to actually let WordSmith choose the texts from the EEPF and the EPD that were written in this period. This can be done by opening the tab File and clicking on Choose Texts. Since the files of the database have been given a specific name structure, following the labelling mentioned by Schlüter in 3.3, it is easy to select the wanted texts. Within the EEPF, for example, by sorting the files according to their type name, that is the year of publication, the researcher is able to recognize four texts from 1518-1535 as the wanted ones at first glance. Then, these texts can be dragged to the selection window on the right hand side (cf. figure 1). After the corresponding texts of the EPD have been added to the selection, the search with the concordancer “Concord” can be started.
Figure 1: Choose Texts; Screenshot from the demo version of WordSmith tools 5
The next step is supposed to shed light on the number of occurrences of the singular pronouns thou, thee, thy and thine within the selected texts. For this purpose, thou/thee/thy/thine is entered into the Search Word field of the concordancer. As a result, it presents 1,225 hits which could all be analysed in more detail, for example by giving them different tags, if one wanted to do so (cf. figure 2). Note that this search query does not include variant forms of spelling, like thi or thine , and therefore does probably not result in a complete list of every instance of the pronouns. A list of all the variants that ideally need to be included can be obtained by use of the "WordList" function of WordSmith. There, by sorting the word list of a particular selection in alphabetical order and scrolling down to "th", one is able to look manually for the variant forms.
Figure 2: Concord; Screenshot from the demo version of WordSmith tools 5

In order to allow for a comparison of the 1,225 occurrences of thou, thee, thy and thine with the number of occurrences of the time spans to follow, one has to put the number in relation to a second one. This could either be the number of occurrences of both the singular and the plural pronouns, i.e. thou, thee, thy, thine, ye, you and your, or the total number of words the selected texts contain. For issues of demonstration, the latter was chosen for the analysis with WordSmith. In order to obtain this number, one must switch to the “WordList” function, have the particular files selected, click on the Make a word list now button and go to the statistics tab in the next window. There, the number of tokens (running words) in text, 136,176, marks the overall number of words included in the selection (cf. figure 3).
Figure 3: WordList; Screenshot from the full version of WordSmith tools 5

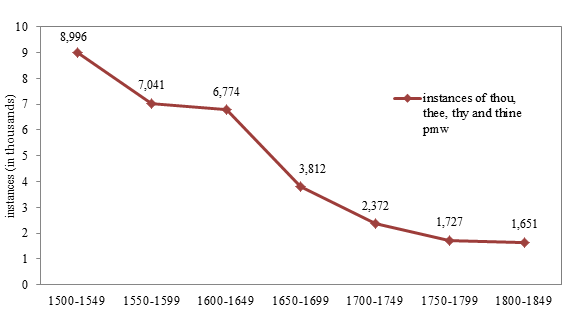
Finally, by calculating the proportion of the two numbers received, one is able to state that 0.89957 % of the words in the texts are either thou, thee, thy or thine. Transferred into a more ordinary linguistic dimension for frequencies, that would be 8.996 pmw (instances per million words).
The following numbers have been calculated by repeating the foregoing procedure for the remaining time spans (note that the AD database was not available for this example and is therefore not included in the calculations):
Time Spans |
Databases Used |
Instances |
Number of words |
Percentage |
Instances pmw |
1500-1549 |
EEPF, EPD |
1,225 |
136,176 |
0.8996 |
8,996 |
1550-1599 |
EEPF, EPD |
25,045 |
3,556,986 |
0.7041 |
7,041 |
1600-1649 |
EEPF, EPD |
30,306 |
4,473,627 |
0.6774 |
6,774 |
1650-1699 |
EEPF, EPD |
33,624 |
8,820,017 |
0.3812 |
3,812 |
1700-1749 |
EEPF (only 1700), EPD, ECF |
23,488 |
9,902,214 |
0.24372 |
2,372 |
1750-1799 |
ECF (1750-1780), NCF (1782-1799), EPD, EAF (1789-1799) |
30,267 |
17,524,358 |
0.1727 |
1,727 |
1800-1849 |
NCF, EPD, EAF |
85,813 |
51,988,064 |
0.1651 |
1,651 |
Eventually, the comparison of the instances per million words of the various time spans allows the following graph to be assembled (cf. figure 4). It visually depicts the validation of the initial claim, namely a gradual decrease of the usage of the singular pronouns thou, thee, thy and thine.
Figure 4: Instances of thou, thee, thy and thine in EEPF, EPD, ECF, NCF and EAF per million words.
Created with the Personal Edition of HelpNDoc: Free PDF documentation generator