The idea of this first example is to compare different items in a fictitious dataset with each other in an easy and understandable way. This is done by allocating one variable to each feature in which one item differs from another. Items that are similar are allocated the same variable values. Obviously this method has several advantages and disadvantages.
Advantages:
- Easy to use
- Relatively easy syntax
Disadvantages:
- Finite number of variables
- Differences of different items can only be described in absolutes (i.e. similar or not similar). There is no way to describe a certain percentage of similarity.
The following part of the webpage aims to show you how to set up such a small-scale comparison:
Before starting, please remember:
What we are basically doing here is scripting / programming, therefore: Syntax is case-sensitive, this means there is a difference between "BEGIN Taxa;" and "begin taxa;"!
Bold and underlined numbers and words indicate that you should change these values according to your own needs.
Step 1
Start SplitsTree4 by clicking the corresponding desktop icon or use the corresponding start menu entry or the .exe file in the program folder.
Step 2
Click on file (upper left corner) and then on file entry. Alternatively you can also press the key combination CTRL + LSHIFT + N. You are then presented with this window:
Step 3
Enter the following:
______________________________
#nexus
BEGIN Taxa;
DIMENSIONS ntax=6;
TAXLABELS
______________________________
#nexus
This tells the program what the following part should be read as, in this case, a nexus file.
BEGIN Taxa;
This tells the program that the following information will include the number of items you wish to compare. The word taxa is a remnant of the program’s origin: bioinformatics.
Here you specify the number of items you wish to compare. Replace the number '6', that is, the value of ntax with the number of different items you wish to compare with each other. Do not forget to put a semicolon after the number.
TAXLABELS
This part tells the program that the following information will include the name of the different items.
The entry window should now look like this:
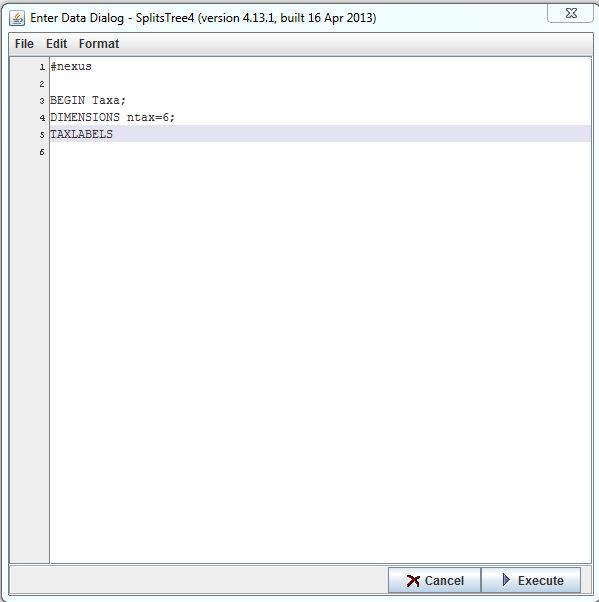
Enter the following:
______________________________
[1] 'language_a'
[2] 'language_b'
[3] 'language_c'
[4] 'language_d'
[5] 'language_e'
[6] 'language_f'
;
END; [Taxa]
______________________________
[1] 'language_a'
[2] 'language_b'
[3] 'language_c'
[4] 'language_d'
[5] 'language_e'
[6] 'language_f'
This part of the syntax tells the program which (unique) name corresponds with each variable. Please remember that the number of unique names specified here should coincide with the number of items set with the variable ntax in the previous step . Also consider that the names should be placed in single quotation marks. Spaces should also be avoided, use the underscore instead.
;
END; [Taxa]
This tells the program that this part of the syntax now ends. Please remember to copy it accurately as both semicolons are needed.
The entry window should now look like this:
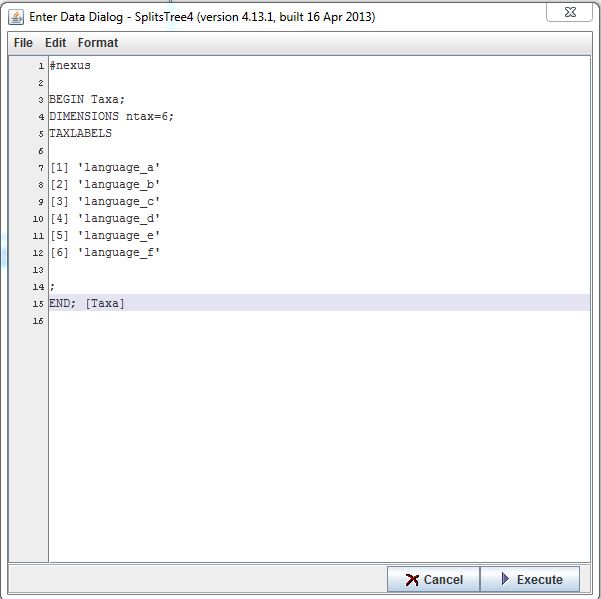
Enter the following:
______________________________
BEGIN Unaligned;
DIMENSIONS ntax=6;
FORMAT
datatype=STANDARD
missing=?
symbols="0 1 2 3 4 5 6 7 8 9"
labels=left
;
______________________________
BEGIN Unaligned;
This tells the program what happens next and should just be copied. Do not forget the semi-colon at the end.
DIMENSIONS ntax=6 nchar=5;
This is another repetition of the number of items you wish to compare. Please remember that this value should correspond with the number of items set with the variable ntax in Step 3 and the number of different names set in Step 4. The value nchar describes how many features you are going to compare in the matrix at the end of the syntax. Consider that this method does not allow different features to have different weights. This means that if your first row correlated with rhoticity and your second row with another feature, there is no way to give one of these features more weight when using this method. The importance of different features can only indirectly be deduced from the resulting NeighborNet visualization.
FORMAT
datatype=STANDARD
This describes the datatype and should not be changed.
missing=?
This describes which symbol will be used in the following matrix to indicate that the relation of the items is unsure and should be ignored by the program.
symbols="0 1 2 3 4 5 6 7 8 9"
This part of the syntax shows the program which symbols are used to differentiate the different items in the following matrix from one another.
Note: the numerals being used in this example have lost their inherent value. This means that the only thing the program is looking for is whether the numbers which are being used to describe the difference / similarity between two items is the same or not.
For example:
Feature 1 |
Feature 2 |
Feature 3 |
|
Language A |
1 |
3 |
5 |
Language B |
1 |
4 |
9 |
In this (pseudo-syntactic) example two different items are compared in three different respects. In the first case (the first column; 1 and 1) both languages are the same. In the second case (the second row; 3 and 4) the two languages are different. In the third case (the third row; 5 and 9) the two languages are different again. Still, there is no difference between case two and case three. The program does not take into account the inherent value of the numerals used. This means that 3 is as close to 4 as it is to 5 or 9. The only thing that matters is that the numbers are not the same.
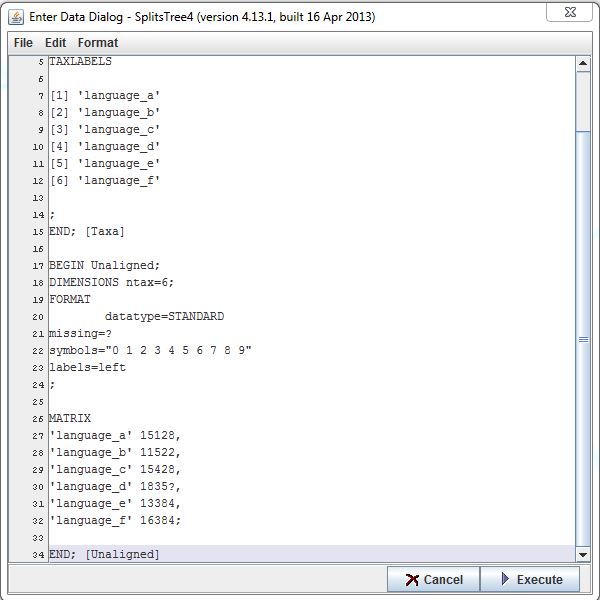
The entry window should now look like this:
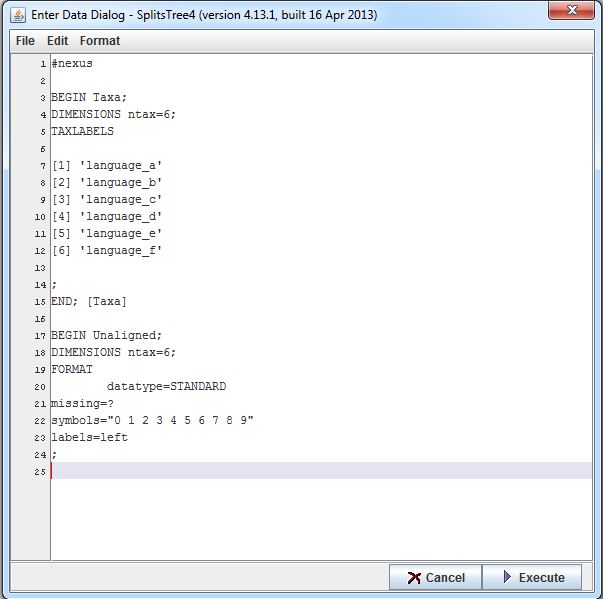
Enter the following:
______________________________
MATRIX
'language_a' 15128,
'language_b' 11522,
'language_c' 15428,
'language_d' 1835?,
'language_e' 13384,
'language_f' 16384;
END; [Unaligned]
______________________________
MATRIX
This tells the program that the following part is a matrix.
'language_a' 15128,
'language_b' 11522,
'language_c' 15428,
'language_d' 1835?,
'language_e' 13384,
'language_f' 16384;
Please remember that the name used in the first row of each line should correspond with the unique names specified in Step 4 of this tutorial. The number of figures (or for that matter, symbols) in the second row of each line should correlate with the number of nchar that has been set in Step 5. Each of these numbers correlates with one feature. Each row of symbols will be compared with each other.
In this example all six examples show the number "1" in the first column. This means that all languages a-f are the same with regard to this feature. The second column features the numbers 5, 1, 5, 8, 3, 6. In this row only the first and third language are the same. All the other items are different from both the first and third and also from each other. Remember that the value of each number is not important. This means that the fourth example language (number 8) is as different from the first (which is number 5) as it is from the second (which is number 1).
Remember to use a semicolon to end the last line, rather than a comma.
The entry window should now look like this:
Step 7
Press the execute button. If you get any error messages, please consider visiting the Troubleshooting page of this companion website.
Created with the Personal Edition of HelpNDoc: Free Web Help generator