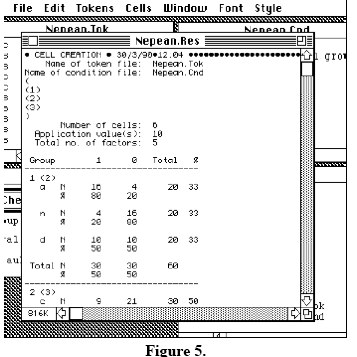
The result file illustrates the program's output. The variable rule program produces the so-called marginal results, which indicate “the relative frequencies and percentages of the variant forms in the data of the dependent variable, either alone... or with the independent variable(s) that have been coded into the token file” (Tagliamonte 2006: 135). The table in Figure 5 shows the distribution of variants of the dependent variable according to the independent variables, which consist of the two factor groups “grammatical category” and “phrase type” and their respective subcategories. There are two lines for each factor within the factor group. The first line states the number (N) of tokens of a dependent variant in a certain context, while the second line shows the percentage (%) that these tokens represent out of the total number in each cell. The first and second row from the end, entitled 'Total' and '%' illustrate the number and percentage of each factor's occurrence together with one of the variants of the independent variable in relation to the total data (cf. Tagliamonte 2006: 163).
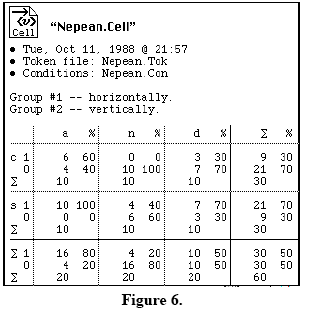
The analyst's task is to scan the result file for certain distinctive features such as data distribution, which is commonly uneven in regards to real language data. However, simply relying on the examination of the result file's marginal results alone can often be misleading, as certain types of interaction might not be readily apparent at first. This is why it is important to cross-tabulate the various factor groups, to find out how they intersect with each other. In the example in Figure 6, for instance, the factor groups “grammatical category” and “phrase type” are cross-tabulated with one another. The factors “a”, “n” and “d” (adjective, noun, determiner) are displayed along the horizontal axis, while the factors “c” and “s” (object noun phrase, subject noun phrase) are shown along the vertical axis. For each possible context the data is divided into two different categories: “1” representing the presence of a plural marker and “0” indicating its absence. The symbol “Σ” indicates the sum of each category (cf. Tagliamonte 2006: 137ff.).
The analyst must now check the marginal results for distinctive features. In Figure 6, for example, it is apparent that the percentage of plural expressions favoring tokens in the context “dc” is identical with the proportion of plural expressions disfavoring tokens in the context “ds”. Furthermore, the two cells “nc” and “as” are categorical, as they do not allow for any variation whatsoever. Of course, this is an important piece of information, which is why cross-tabulation is an essential part of a variation analysis, as otherwise such “lumps”, “clumps”, “hollows” and “dips” within the data would never be revealed, thus causing the results to be inaccurate (cf. Tagliamonte 2006: 229ff.).
Created with the Personal Edition of HelpNDoc: Write EPub books for the iPad