This section will name a few books, articles and online publications which are useful for finding further information on using the Internet as a corpus and as a source of general information.
http://www.linguistik-online.com/28_06/bickel.html (12.01.2011).

Bickel’s article is very short and superficially deals with the Internet as a linguistic corpus. After a brief introduction, the author deals with search engines and the question of whether the Internet is suitable as a basis for lexicographic and linguistic research. He conducts a test with AltaVista in order to find out whether the Internet can be trusted or whether Internet search results are likely to be significantly affected by any distorting or deviating factors. Unlike many other authors, Bickel supports the usage of the Internet for linguistic research as it has many advantages, which he names at the end of the article.
http://www.bubenhofer.com/korpuslinguistik/kurs/index.php?id=web_grundlagen.html (12.01.2011).

Noah Bubenhofer works as a linguist for the Institut für Deutsche Sprache in Mannheim and offers a theoretical and practical introduction to corpus linguistics on his German website, which is used actively by different universities and institutes. First of all, he offers a definition of ‘corpus’ and introduces different types of corpora. Furthermore, he explains how a corpus is compiled, annotated and how it can be used.
Especially helpful is the chapter ‘Web als Korpus’, as it briefly explains how the Internet is structured and how search engines work. Even people who are not that experienced in working with the Internet can understand Bubenhofer’s short and crisp expositions. In this chapter, Bubenhofer also offers various exercises concerning search engines and their facilities, which can help to familiarize oneself with the usage of Google, Altavista and such like. Additionally, he points out various problems of the Internet and gives examples of how the Web can be used for linguistic research.
Although the Web page basically deals with German corpus linguistics, it provides helpful information on the use of the Internet for linguistic research and is definitely worth a click.

This book explains everything there is to know about search engines. It was not edited by academics alone, but also by two people from the search engine business, who work for Yahoo! and Google respectively. The book consists of eleven chapters:
This book provides a lot of background information on search engines. It is, however, very technical and contains a lot of mathematical formulas. For someone with a liking for the technology and good technological understanding it will be helpful in understanding the way search engines work and also in perfecting the formulation of a query. For the rest it will be a difficult and frustrating read.
Online version:
http://scidok.sulb.uni-saarland.de/volltexte/2009/2148/pdf/Diemer_29_57.pdf (12.01.2011)
Diemer’s article can be downloaded as a PDF-file.
It deals with the Internet as a corpus and is therefore a helpful additional source to Hundt’s chapter. After a general introduction to corpus linguistics and theoretical linguistics, Diemer provides information about the development in corpus linguistics in the last decades starting with the Brown Corpus in the 60s. In a second chapter, he outlines questions, methods and possible applications of modern corpus linguistics according to Charles F. Meyer. He discusses whether the use of the Internet is the future of corpus linguistics and presents several examples of the linguistic use of Google. At the end of the article, Diemer gives an outlook on future developments in corpus linguistics.

This book is very useful if one wants to look more deeply into the use of the Internet as a corpus or for corpus building. It consists of four sections that look into every aspect of using the web for corpus linguistics. It provides further information and explanations on topics that were only briefly addressed in the article.
The four sections are:
This book is definitely worth a look if one is interested in using the Internet as a source for linguistic data. It gives a good insight into programs like WebCorp or KWiCFinder, which make searching the Web easier. Also, there is a short abstract at the beginning of every article, so it is not necessary to read them all to know whether they are useful or not.

Kilgarriff’s article offers a further short introduction to the topic of using the Internet as a corpus. It gives a brief summary of both the advantages and disadvantages of the approach.
Kilgarriff also provides a short outlook on how the Internet could be used as a more reliable source of information and linguistic data.

Ó Dochartaigh’s book consists of ten chapters dealing with the Internet as a source for scientific research. It was written as an introduction to the Internet and its possibilities for research for students and researchers in the social sciences and offers extremely helpful information on the following topics:
Although Ó Dochartaigh’s book is not specialised on linguistic research and corpus linguistics, it provides helpful basic information for getting acquainted with the scientific usage of the Internet.

This book deals with corpus linguistics in general, and among others addresses the topic “The Web as Corpus”. It is organized into six chapters:
The fourth chapter of this book is highly recommendable if one is interested in using WebCorp for an online search. The book was edited by Antoinette Renouf and Andrew Kehoe from the Research and Development Unit for English Studies at the University of Central England in Birmingham, which developed WebCorp. The information given is therefore very useful. This book also gives a short abstract before the articles.

This web page provides information about the KWiCFinder program. It gives step-by-step instructions on how to use the program. It also offers the program as free download. Furthermore, it names various articles by the author of KWiCFinder, which can be downloaded free of charge as PDF-files.
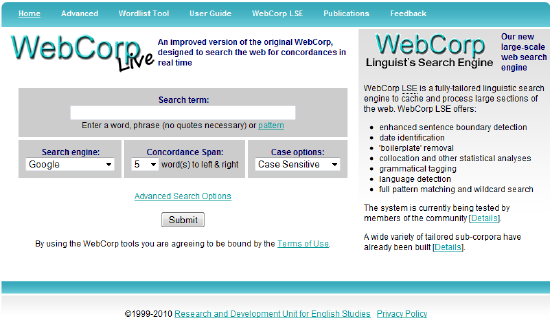
This web page is the site of WebCorp. Apart from the actual simple and advanced search, this site also contains a detailed and useful user guide and additional publications on WebCorp that can be downloaded as PDF-files.
Created with the Personal Edition of HelpNDoc: Single source CHM, PDF, DOC and HTML Help creation